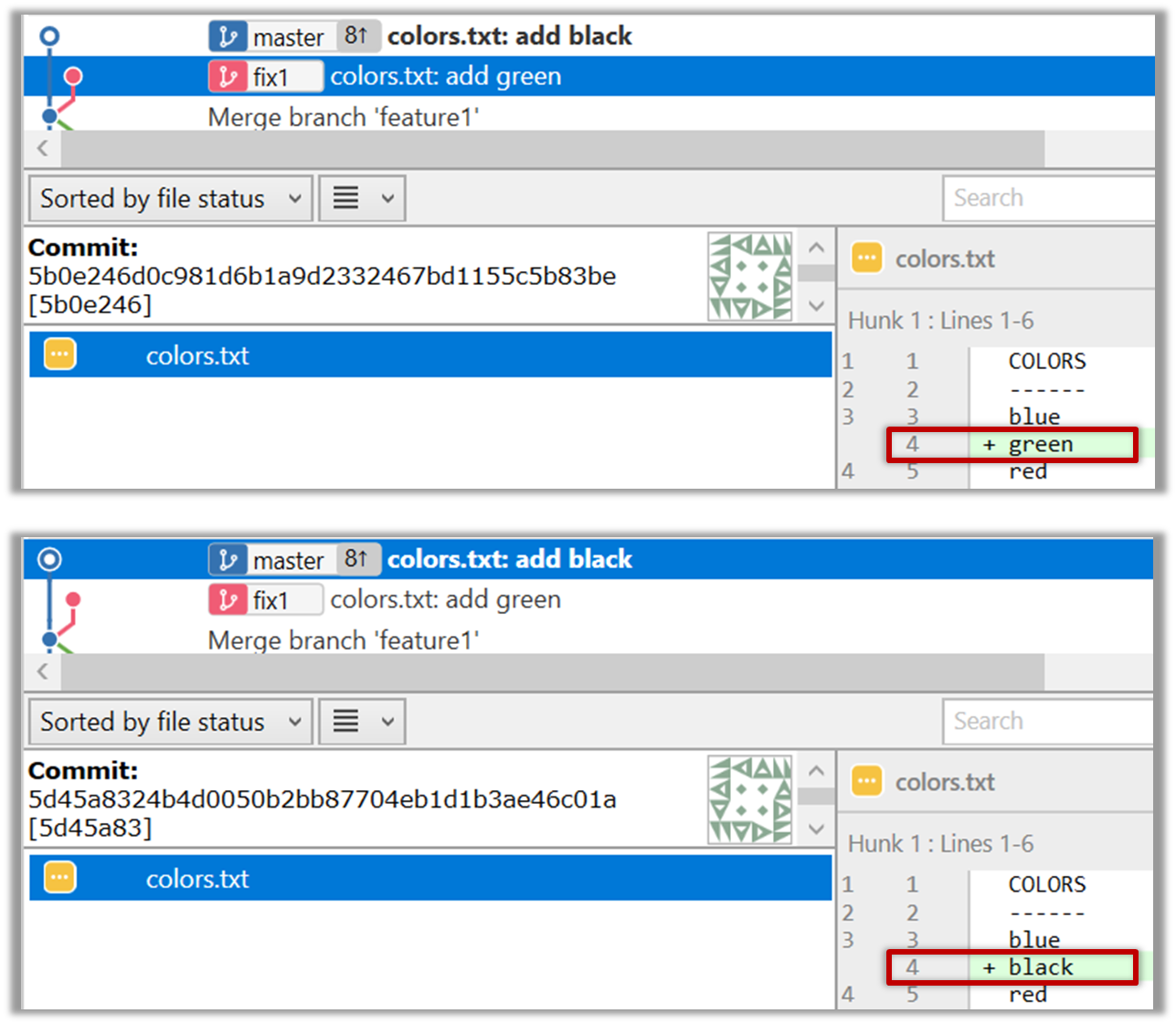
You can organize your types (i.e., classes, interfaces, enumerations, etc.) into packages for easier management (among other benefits).
To create a package, you put a package statement at the very top of every source file in that package. The package statement must be the first line in the source file and there can be no more than one package statement in each source file. Furthermore, the package of a type should match the folder path of the source file. Similarly, the compiler will put the .class files in a folder structure that matches the package names.
The Formatter class below (in <source folder>/seedu/tojava/util/Formatter.java file) is in the package seedu.tojava.util. When it is compiled, the Formatter.class file will be in the location <compiler output folder>/seedu/tojava/util:
package seedu.tojava.util;
public class Formatter {
public static final String PREFIX = ">>";
public static String format(String s){
return PREFIX + s;
}
}
Package names are written in all lower case (not camelCase), using the dot as a separator. Packages in the Java language itself begin with java. or javax. Companies use their reversed Internet domain name to begin their package names.
For example, com.foobar.doohickey.util can be the name of a package created by a company with a domain name foobar.com
To use a public package member from outside its package, you must do one of the following:
- Use the fully qualified name to refer to the member
- Import the package or the specific package member
The Main class below has two import statements:
import seedu.tojava.util.StringParser: imports the class StringParser in the seedu.tojava.util packageimport seedu.tojava.frontend.*: imports all the classes in the seedu.tojava.frontend package
package seedu.tojava;
import seedu.tojava.util.StringParser;
import seedu.tojava.frontend.*;
public class Main {
public static void main(String[] args) {
String status = seedu.tojava.logic.Processor.getStatus();
StringParser sp = new StringParser();
Ui ui = new Ui();
Message m = new Message();
}
}
Note how the class can still use the Processor without importing it first, by using its fully qualified name seedu.tojava.logic.Processor
Importing a package does not import its sub-packages, as packages do not behave as hierarchies despite appearances.
import seedu.tojava.frontend.* does not import the classes in the sub-package seedu.tojava.frontend.widget.
If you do not use a package statement, your type doesn't have a package -- a practice not recommended (except for small code examples) as it is not possible for a type in a package to import a type that is not in a package.
Optionally, a static import can be used to import static members of a type so that the imported members can be used without specifying the type name.
The class below uses static imports to import the constant PREFIX and the method format() from the seedu.tojava.util.Formatter class.
import static seedu.tojava.util.Formatter.PREFIX;
import static seedu.tojava.util.Formatter.format;
public class Main {
public static void main(String[] args) {
String formatted = format("Hello");
boolean isFormatted = formatted.startsWith(PREFIX);
System.out.println(formatted);
}
}
package seedu.tojava.util;
public class Formatter {
public static final String PREFIX = ">>";
public static String format(String s){
return PREFIX + s;
}
}
Note how the class can use PREFIX and format() (instead of Formatter.PREFIX and Formatter.format()).
When using the commandline to compile/run Java, you should take the package into account.
If the seedu.tojava.Main class in defined in the file Main.java,
- when compiling from the
<source folder>, the command is:
javac seedu/tojava/Main.java
- when running it from the
<compiler output folder>, the command is:
java seedu.tojava.Main