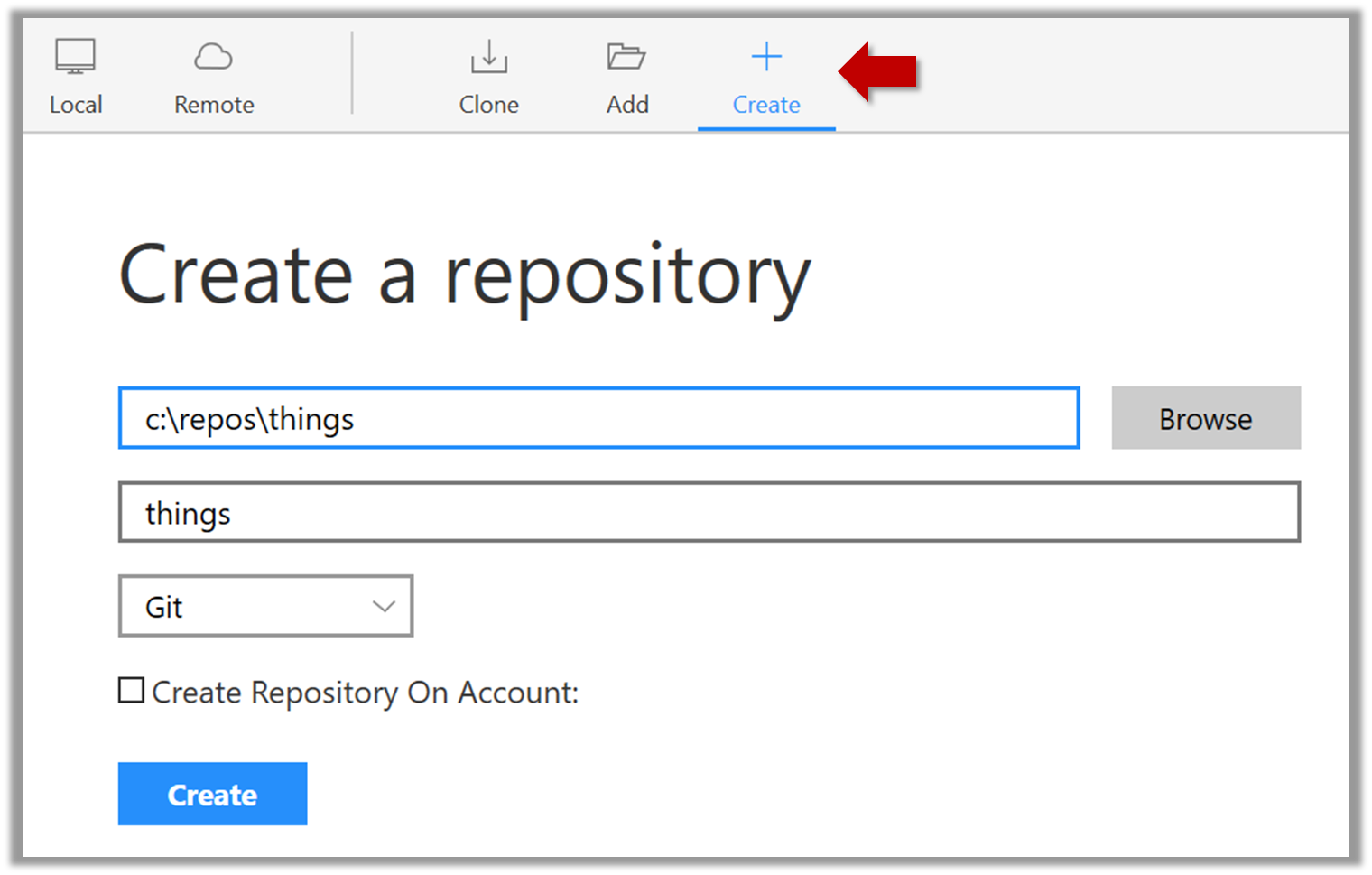
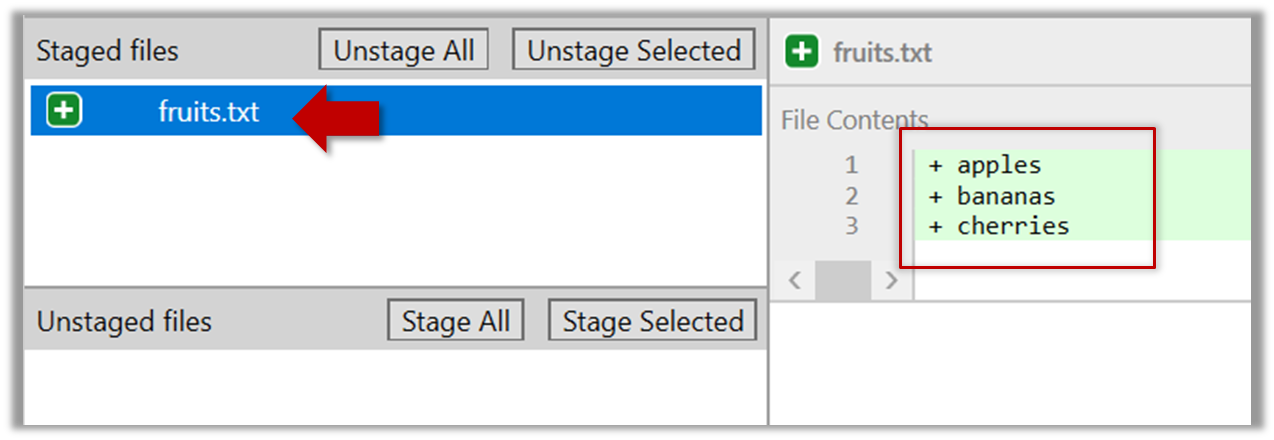
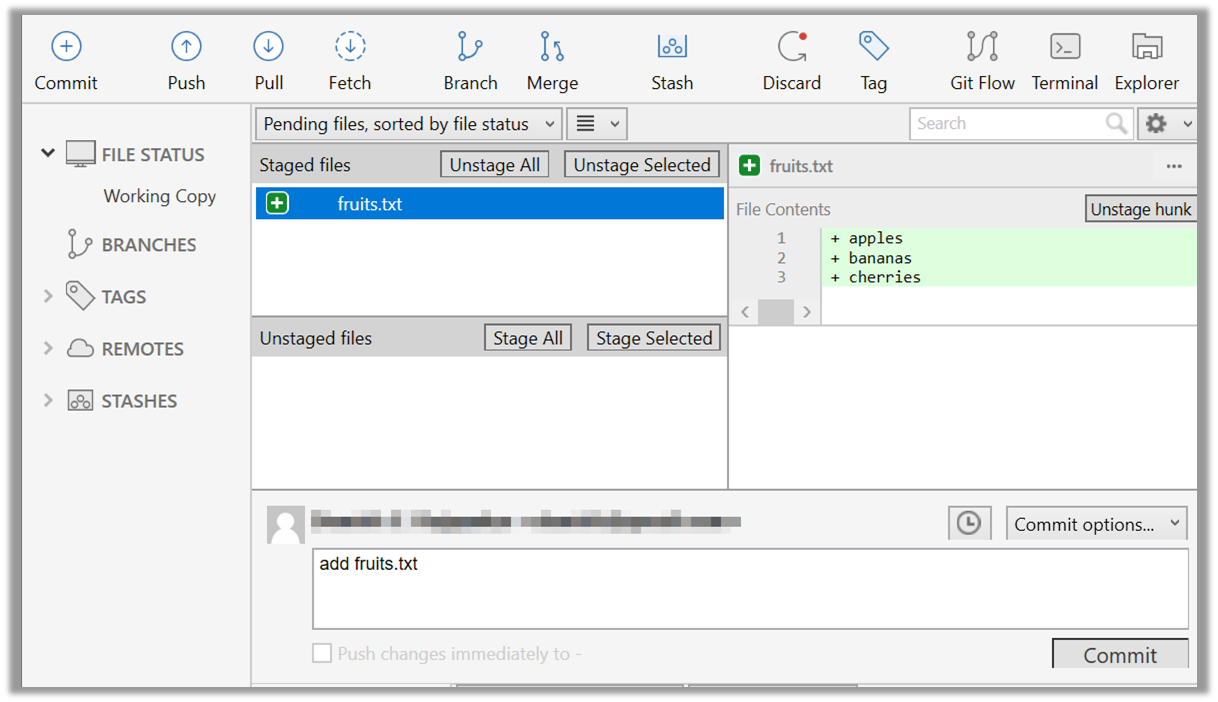
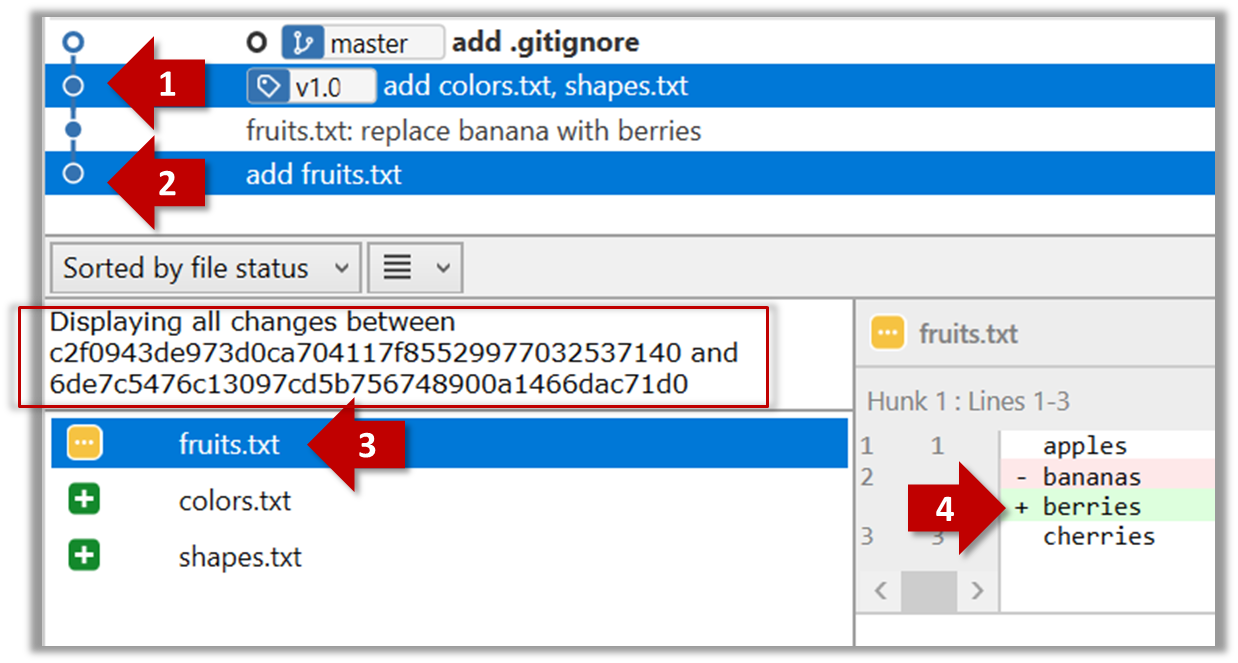
Every object has both state (data) and behavior (operations on data). In that, they’re not much different
from ordinary physical objects. It’s easy to see how a mechanical device, such as a pocket watch or a piano,
embodies both state and behavior. But almost anything that’s designed to do a job does, too. Even simple things
with no moving parts such as an ordinary bottle combine state (how full the bottle is, whether or not it’s open,
how warm its contents are) with behavior (the ability to dispense its contents at various flow rates, to be opened
or closed, to withstand high or low temperatures).
It’s this resemblance to real things that gives objects much of their power and appeal. They can not only model
components of real systems, but equally as well fulfill assigned roles as components in software systems.
-- Object-Oriented Programming with Objective-C, Apple
Object Oriented Programming (OOP) views the world as a network of interacting objects.
A real world scenario viewed as a network of interacting objects:
You are asked to find out the average age of a group of people Adam, Beth, Charlie, and Daisy. You take a piece of paper and pen, go to each person, ask for their age, and note it down. After collecting the age of all four, you enter it into a calculator to find the total. And then, use the same calculator to divide the total by four, to get the average age. This can be viewed as the objects You, Pen, Paper, Calculator, Adam, Beth, Charlie, and Daisy interacting to accomplish the end result of calculating the average age of the four persons. These objects can be considered as connected in a certain network of certain structure.
OOP solutions try to create a similar object network inside the computer’s memory – a sort of a virtual simulation of the corresponding real world scenario – so that a similar result can be achieved programmatically.
OOP does not demand that the virtual world object network follow the real world exactly.
Our previous example can be tweaked a bit as follows:
- Use an object called
Main to represent your role in the scenario.
- As there is no physical writing involved, we can replace the
Pen and Paper with an object called AgeList that is able to keep a list of ages.
Every object has both state (data) and behavior (operations on data).
| Object |
Real World? |
Virtual World? |
Example of State (i.e. Data) |
Examples of Behavior (i.e. Operations) |
| Adam |
|
|
Name, Date of Birth |
Calculate age based on birthday |
| Pen |
|
- |
Ink color, Amount of ink remaining |
Write |
| AgeList |
- |
|
Recorded ages |
Give the number of entries, Accept an entry to record |
| Calculator |
|
|
Numbers already entered |
Calculate the sum, divide |
| You/Main |
|
|
Average age, Sum of ages |
Use other objects to calculate |
Every object has an interface and an implementation.
Every real world object has:
- an interface through which other objects can interact with it
- an implementation that supports the interface but may not be accessible to the other object
The interface and implementation of some real-world objects in our example:
- Calculator: the buttons and the display are part of the interface; circuits are part of the implementation.
- Adam: In the context of our 'calculate average age' example, the interface of Adam consists of requests that adam will respond to, e.g. "Give age to the nearest year, as at Jan 1st of this year" "State your name"; the implementation includes the mental calculation Adam uses to calculate the age which is not visible to other objects.
Similarly, every object in the virtual world has an interface and an implementation.
The interface and implementation of some virtual-world objects in our example:
Adam: the interface might have a method getAge(Date asAt); the implementation of that method is not visible to other objects.
Objects interact by sending messages. Both real world and virtual world object interactions can be viewed as objects sending message to each other. The message can result in the sender object receiving a response and/or the receiver object’s state being changed. Furthermore, the result can vary based on which object received the message, even if the message is identical (see rows 1 and 2 in the example below).
Examples:
| World |
Sender |
Receiver |
Message |
Response |
State Change |
| Real |
You |
Adam |
"What is your name?" |
"Adam" |
- |
| Real |
as above |
Beth |
as above |
"Beth" |
- |
| Real |
You |
Pen |
Put nib on paper and apply pressure |
Makes a mark on your paper |
Ink level goes down |
| Virtual |
Main |
Calculator (current total is 50) |
add(int i): int i = 23 |
73 |
total = total + 23 |